MAIN-VC
Abstract
One-shot voice conversion aims to change the timbre of any source speech to match that of the unseen target speaker with only one speech sample. Existing methods face difficulty in satisfactory speech representation disentanglement and suffer from sizable networks. We propose a method to effectively disentangle with a concise neural network. Our model learns clean speech representations via siamese encoders with the enhancement of the designed mutual information estimator. The siamese structure and the newly designed convolution module contribute to the lightweight of our model while ensuring the performance in diverse voice conversion tasks.
Overview
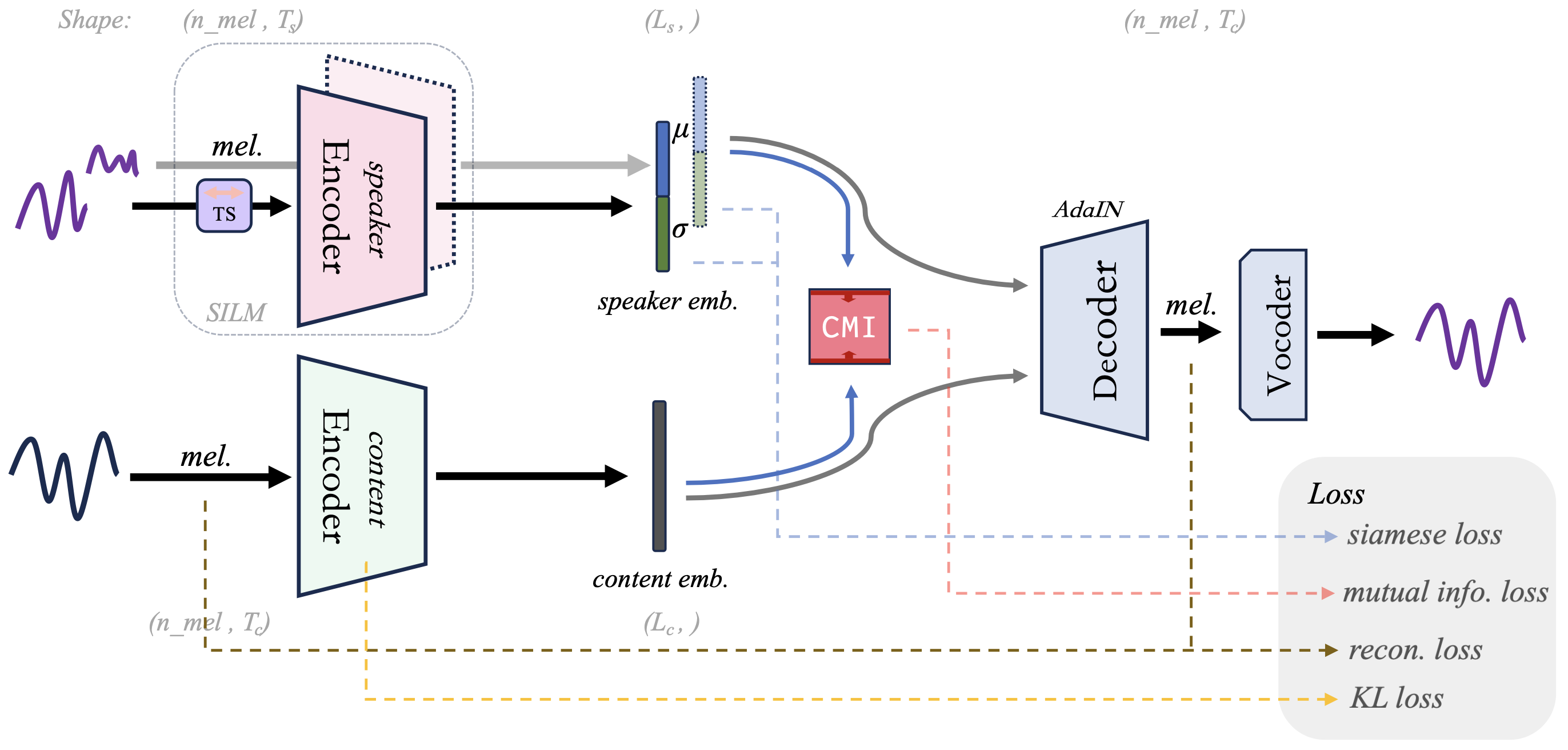
Figure.1 The Architecture of MAIN-VC
Audio Samples in VC Tasks
Audio samples are taken from the VCTK dataset and AISHELL dataset.
| Source | Target | Baseline | MAIN-VC | |
|---|---|---|---|---|
| F2F | ||||
| M2M | ||||
| F2M | ||||
| M2F |
| Source | Target | Baseline | MAIN-VC | |
|---|---|---|---|---|
| F2F | ||||
| M2M | ||||
| F2M | ||||
| M2F |
| Source | Target | MAIN-VC | |
|---|---|---|---|
| M2E F2M | |||
| M2E M2F | |||
| M2E F2M | |||
| M2E M2M |
Mel-Spectrogram Samples in One-shot VC
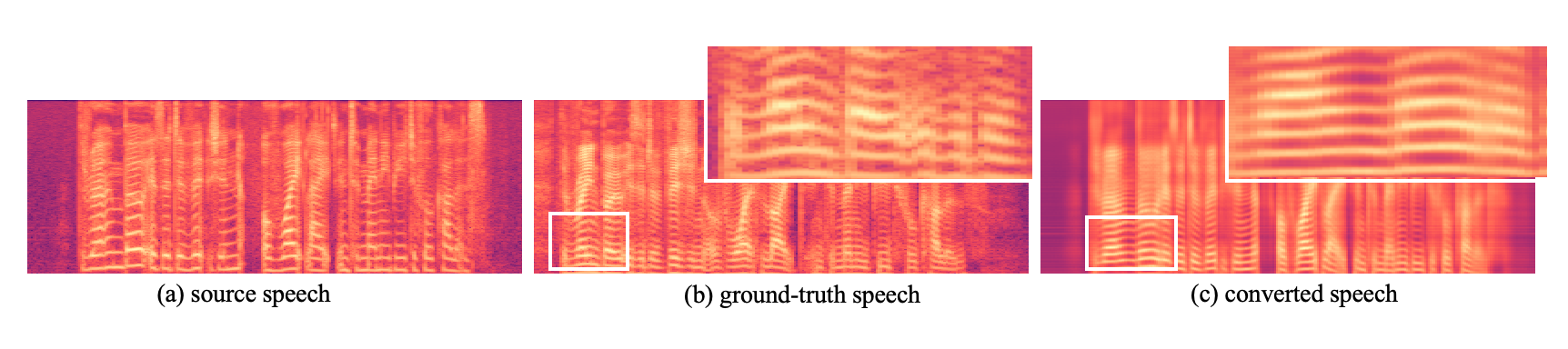
Figure.2 VC task "The rainbow is a division of white light into many beautiful colors."

Figure.3 VC task "People look, but no one finds it."

Figure.4 VC task "Some have accepted it as a miracle without physical explanation."
Ablation Study
Compare MAIN-VC with:
- w/o CMI: the proposed method without CMI module,
- w/o SE: the proposed method without siamese encoder.
| Source | Target | w/o CMI | w/o SE | MAIN-VC |
|---|---|---|---|---|